Схемы и шаблоны в СУБД PostgreSQL
Базы данных и шаблоны
Когда мы создаём новые кластер командой initdb у нас создается 3 одинаковые базы данных:
postgrestemplate0template1
postgres@s-pg13:~$ psql
Timing is on.
psql (13.3)
Type "help" for help.
postgres@postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 |
template0 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(3 rows)
База postgres используется, чтобы по умолчанию к ней подключаться. Принципиально она не нужна, но есть приложения которым она может понадобится, поэтому лучше её не удалять.
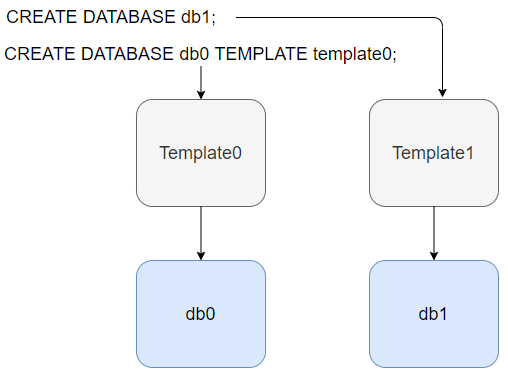
Две дополнительные базы template0 и template1 — это шаблоны. Новая база всегда создается путём копирования из другой шаблонной базы. По умолчанию для шаблона используется база template1. Поэтому, если у вас есть расширения, которыми вы пользуетесь, можете их заранее создать в template1.
Основная задача базы template0 заключается в том, что бы она никогда не менялась. Она используется, например при загрузке базы из дампа. Вначале вы создаёте базу из template0, а затем туда заливаете сохранённый дамп. Также база template0 позволяет создавать базы с использованием
категорий локалей
не по умолчанию (LC_COLLATE, LC_CTYPE).
Схемы
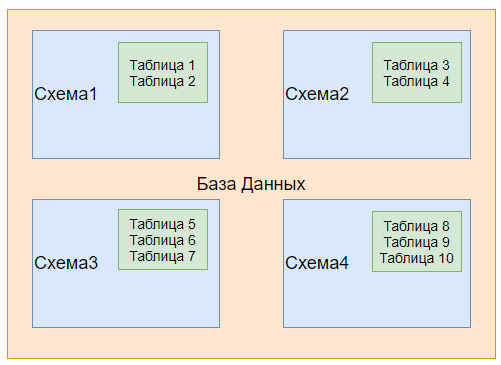
Схема — это пространство имён для объектов внутри базы данных.
Суть работы схемы можно представить так: мы все складываем не все в одну большую кучу, а по небольшим отдельным кучкам. Например, как в файловой системе, всё кладем не в один каталог, а раскладываем по подкаталогам.
Вот пример работы со схемами! В одну схему поместим объекты для модуля «логистика», а в другую для модуля «финансы» и так далее.
В базе данных может быть несколько схем. По умолчанию существует две глобальные схемы. Глобальные они потому-что не принадлежат какой-то определённой базе данных:
pg_catalog— служебная схема (её ещё называют системный каталог), присутствует во всех базах данных, например там находится представлениеpg_tables;public— общая схема, присутствует во всех базах данных и по умолчанию все объекты создаются в ней.
Также вы можете создать свои дополнительные схемы.
Путь поиска
Так называемое «Квалифицированное имя» состоит из явно указанной схемы и имени объекта (как абсолютный путь в файловой системе). Например: <схема.имя>.
Если мы не указываем схему, то нужно понять, в какой схеме искать или создавать объект. Определяют схему с помощью пути поиска, который задается параметром search_path.
В параметре search_path можно через запятую перечислить схемы, в которых нужно искать объект, если мы не указываем схему явно. search_path это что-то вроде переменной окружения PATH в Linux, для поиска команд.
Из search_path исключаются:
- несуществующие схемы;
- схемы к которым нет доступа.
А некоторые схемы всегда добавляются в search_path, даже если мы их туда не запишем. Например pg_catalog.
Реальное значение search_path показывает функция current_schemas().
postgres@postgres=# SELECT current_schemas(true);
current_schemas
---------------------
{pg_catalog,public}
(1 row)
Time: 1,945 ms
При создании нового объекта, он будет помещаться в первую указанную в search_path схему. Если посмотреть пример выше, то так как у нас нет права писать в схему pg_catalog, объекты будут создаваться в public.
Специальные схемы, временные объекты
К специальным схемам относят:
- public — по умолчанию входит в путь поиска, если ничего не менять, все объекты будут в этой схеме.
- Схема, одноимённая с пользователем — по умолчанию входит в
search_path, но не существует. Если сделать, например схемуpostgres, то пользовательpostgresбудет по умолчанию работать с этой схемой. - pg_catalog — схема для объектов системного каталога. Если pg_catalog не прописан, то это схема будет там подразумеваться первой.
Временные таблицы — существуют на время сеанса или транзакции. Они не журналируются и не попадают в общую память. Чтобы реализовать временную таблицу в postgres применяет временные схемы.
Схема pg_temp_N — автоматически создается для временных таблиц. Такая схема тоже по умолчанию находится в search_path. По окончанию все объекты временной схемы удаляются, а сама схема остается. Оставшаяся временная схема может использоваться для новых временных таблиц, новой транзакции или сеанса.
Практика
Список баз
Как мы уже видели с помощью команды \l, у нас действительно 3 базы. Сейчас мы подключены к базе postgres. Тут мы можем обратиться к представлению pg_database и посмотреть на список баз из этого представления:
postgres@postgres=# SELECT datname, datistemplate, datallowconn, datconnlimit FROM pg_database;
datname | datistemplate | datallowconn | datconnlimit
-----------+---------------+--------------+--------------
postgres | f | t | -1
template1 | t | t | -1
template0 | t | f | -1
(3 rows)
Time: 0,875 ms
Здесь мы видим:
datname— имя базы данных;datistemplate— является ли база данных шаблоном;datallowconn— разрешены ли соединения с базой данных;datconnlimit— максимальное количество соединений (-1 = без ограничений).
Настройка шаблона template1
Проверим, доступна ли нам функция шифрования в этой базе, если не доступна, то создадим необходимое расширение и повторим проверку:
postgres@postgres=# \c template1
You are now connected to database "template1" as user "postgres".
postgres@template1=# SELECT digest('Hello, world!', 'md5');
ERROR: function digest(unknown, unknown) does not exist
LINE 1: SELECT digest('Hello, world!', 'md5');
^
HINT: No function matches the given name and argument types. You might need to add explicit type casts.
Time: 2,081 ms
postgres@template1=# CREATE EXTENSION pgcrypto;
CREATE EXTENSION
Time: 24,470 ms
postgres@template1=# SELECT digest('Hello, world!', 'md5');
digest
------------------------------------
\x6cd3556deb0da54bca060b4c39479839
(1 row)
Time: 0,419 ms
Теперь создадим новую базу данных и так как она была создана из шаблона template1, то и расширение pgcrypto здесь уже установлено:
postgres@postgres=# \c postgres
You are now connected to database "postgres" as user "postgres".
postgres@postgres=# CREATE DATABASE db;
CREATE DATABASE
Time: 103,788 ms
postgres@postgres=# \c db
You are now connected to database "db" as user "postgres".
postgres@db=# SELECT digest('Hello, world!', 'md5');
digest
------------------------------------
\x6cd3556deb0da54bca060b4c39479839
(1 row)
Time: 0,868 ms
Выше мы вначале отключились от базы template1, так как использовать шаблон можно только, если к нему никто не подключен!
Редактирование базы
Теперь переименуем созданную базу данных (ALTER DATABASE … RENAME TO …), предварительно отключившись от неё:
postgres@db=# \c postgres
You are now connected to database "postgres" as user "postgres".
postgres@postgres=# ALTER DATABASE db RENAME TO appdb;
ALTER DATABASE
Time: 1,164 ms
postgres@postgres=# SELECT datname, datistemplate, datallowconn, datconnlimit FROM pg_database;
datname | datistemplate | datallowconn | datconnlimit
-----------+---------------+--------------+--------------
postgres | f | t | -1
template1 | t | t | -1
template0 | t | f | -1
appdb | f | t | -1
(4 rows)
Time: 0,434 ms
С помощью ALTER DATABASE можно менять и другие параметры, например число доступных подключений:
postgres@postgres=# ALTER DATABASE appdb CONNECTION LIMIT 10;
ALTER DATABASE
Time: 0,456 ms
postgres@postgres=# SELECT datname, datistemplate, datallowconn, datconnlimit FROM pg_database;
datname | datistemplate | datallowconn | datconnlimit
-----------+---------------+--------------+--------------
postgres | f | t | -1
template1 | t | t | -1
template0 | t | f | -1
appdb | f | t | 10
(4 rows)
Time: 0,202 ms
Смотрим размер базы данных
Размер базы данных можно считать с помощью функции pg_database_size(). Для перевода из байтов в более удобочитаемые единицы, можно использовать функцию pg_size_pretty():
postgres@postgres=# SELECT pg_database_size('appdb');
pg_database_size
------------------
7787055
(1 row)
Time: 1,750 ms
postgres@postgres=# SELECT pg_size_pretty(pg_database_size('appdb'));
pg_size_pretty
----------------
7605 kB
(1 row)
Time: 1,247 ms
Вот мы и узнали размер пустой базы!
Работа со схемами
Список схем можно узнать с помощью команды \dn:
postgres@postgres=# \dn
List of schemas
Name | Owner
--------+----------
public | postgres
(1 row)
Это не все схемы, здесь исключены служебные схемы!
Создадим новую схему, предварительно подключившись к нашей базе:
postgres@postgres=# \c appdb
You are now connected to database "appdb" as user "postgres".
postgres@appdb=# CREATE SCHEMA app;
CREATE SCHEMA
Time: 0,927 ms
postgres@appdb=# \dn
List of schemas
Name | Owner
--------+----------
app | postgres
public | postgres
(2 rows)
На путь поиска схем можно посмотреть с помощью search_path:
postgres@appdb=# SHOW search_path;
search_path
-----------------
"$user", public
(1 row)
Time: 0,248 ms
Это означает, что при создании таблицы, она попытается попасть в схему "$user" (postgres), но раз такой схемы нет, то попадет в схему public. При обращении к таблице она будет искаться в начале в $user, а затем в public!
Дополнительно можем посмотреть текущие схемы, в этой базе данных с помощью функции current_schemas():
postgres@appdb=# SELECT current_schemas(true);
current_schemas
---------------------
{pg_catalog,public}
(1 row)
Time: 0,343 ms
Здесь мы видим служебную схему pg_catalog, но к ней нет доступа. Поэтому судя по пути поиска и по текущим схемам, можем сказать что по умолчанию таблицы будут создаваться в схеме public.
Теперь создадим таблицу t, в ней создадим строку и с помощью команды \dt посмотрим в какой схеме оказалась эта таблица:
postgres@appdb=# CREATE TABLE t(s text);
CREATE TABLE
Time: 4,398 ms
postgres@appdb=# INSERT INTO t VALUES ('Я - таблица t');
INSERT 0 1
Time: 1,172 ms
postgres@appdb=# \dt
List of relations
Schema | Name | Type | Owner
--------+------+-------+----------
public | t | table | postgres
(1 row)
Таблицы можно перемещать между схемами с помощью ALTER TABLE ... SET SCHEMA .... Если схемы нет в пути поиска, то к таблицам в этой схеме нужно обращаться по полному пути:
postgres@appdb=# ALTER TABLE t SET SCHEMA app;
ALTER TABLE
Time: 0,916 ms
postgres@appdb=# SELECT * FROM app.t;
s
---------------
Я - таблица t
(1 row)
Time: 0,372 ms
postgres@appdb=# SELECT * FROM t;
ERROR: relation "t" does not exist
LINE 1: SELECT * FROM t;
^
Time: 0,226 ms
Выше мы видим, что не указав полный путь мы получили ошибку!
Установить путь поиска можно так:
postgres@appdb=# SET search_path = public, app;
SET
Time: 0,203 ms
postgres@appdb=# SELECT * FROM t;
s
---------------
Я - таблица t
(1 row)
Time: 0,205 ms
Но это установит путь только для текущего сеанса!
Установить этот параметр для базы, а не для сеанса можно с помощью ALTER DATABASE ... SET search_path = ...:
appdb=# ALTER DATABASE appdb SET search_path = public, app;
ALTER DATABASE
Выше команда означает, что при подключении к базе appdb будет выполняться команда SET search_path = public, app.
Теперь создадим временную таблицу с таким-же именем t и посмотрим что из этого выйдет:
postgres@appdb=# CREATE TEMP TABLE t(s text);
CREATE TABLE
Time: 1,908 ms
postgres@appdb=# \dt
List of relations
Schema | Name | Type | Owner
-----------+------+-------+----------
pg_temp_3 | t | table | postgres
(1 row)
Мы видим только временную таблицу, а первую созданную таблицу уже не видим в списке баз!
Посмотрим на текущий путь поиска с помощью функции current_schemas (). А затем вставим строку во временную таблицу и прочитаем её. И далее прочитаем строки из обычной таблицы используя полный путь:
postgres@appdb=# SELECT current_schemas(true);
current_schemas
-----------------------------------
{pg_temp_3,pg_catalog,public,app}
(1 row)
Time: 0,202 ms
postgres@appdb=# INSERT INTO t VALUES ('Я - временная таблица');
INSERT 0 1
Time: 0,608 ms
postgres@appdb=# SELECT * FROM app.t;
s
---------------
Я - таблица t
(1 row)
Time: 0,191 ms
postgres@appdb=# SELECT * FROM pg_temp.t;
s
-----------------------
Я - временная таблица
(1 row)
Time: 0,203 ms
При выходе из сеанса все объекты во временной схеме уничтожаются:
postgres@appdb=# \c appdb
You are now connected to database "appdb" as user "postgres".
postgres@appdb=# SELECT current_schemas(true);
current_schemas
-------------------------
{pg_catalog,public,app}
(1 row)
Time: 0,373 ms
postgres@appdb=# SELECT * FROM t;
s
---------------
Я - таблица t
(1 row)
Time: 0,359 ms
Удаление схемы и базы
Схему нельзя удалить, если в ней есть какие-нибудь объекты. А для удаления схемы вместе с объектами нужно использовать опцию CASCADE:
postgres@appdb=# DROP SCHEMA app;
ERROR: cannot drop schema app because other objects depend on it
DETAIL: table t depends on schema app
HINT: Use DROP ... CASCADE to drop the dependent objects too.
Time: 0,612 ms
postgres@appdb=# DROP SCHEMA app CASCADE;
NOTICE: drop cascades to table t
DROP SCHEMA
Time: 1,175 ms
Базу данных можно удалить, если к ней нет активных подключений:
postgres@appdb=# \c postgres
You are now connected to database "postgres" as user "postgres".
postgres@postgres=# DROP DATABASE appdb;
DROP DATABASE
Time: 14,367 ms
Если понравилась статья, подпишись на мой канал в VK или Telegram .